ACID Properties in Databases
What is ACID?
ACID is a set of four properties that guarantee database transactions are processed reliably. These properties ensure data integrity even in the event of system failures, crashes, or concurrent access.
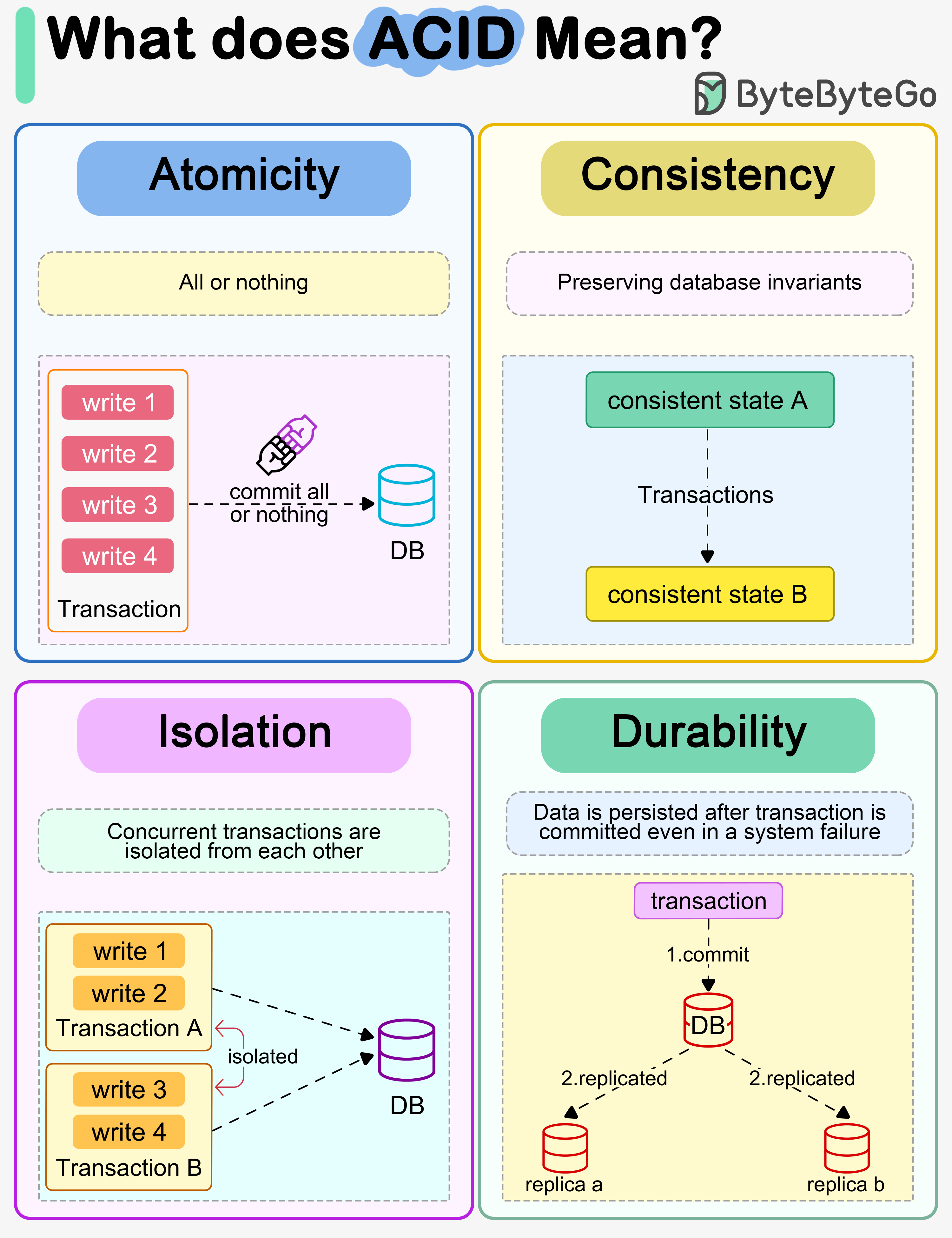
Atomicity
The writes in a transaction are executed all at once and cannot be broken into smaller parts. If there are faults when executing the transaction, the writes in the transaction are rolled back.
So atomicity means "all or nothing".
How it works
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- If this fails here, the first UPDATE is rolled back
COMMIT;
- The database uses a transaction log (write-ahead log) to track changes
- If the transaction fails or is rolled back, the database undoes all partial changes
- The client never sees a partially completed transaction
Consistency
Unlike "consistency" in CAP theorem (which means every read receives the most recent write or an error), here consistency means preserving database invariants. Any data written by a transaction must be valid according to all defined rules and maintain the database in a good state.
How it works
- Constraints —
NOT NULL,UNIQUE,CHECK,FOREIGN KEYenforce rules - Triggers — custom validation logic before/after writes
- Application-level checks — business rules validated within the transaction
-- CHECK constraint ensures balance never goes negative
CREATE TABLE accounts (
id INT PRIMARY KEY,
balance DECIMAL(10,2) CHECK (balance >= 0)
);
If a transaction would violate any constraint, it is rejected and rolled back.
Atomicity guarantees that a transaction is all-or-nothing. Consistency guarantees that the "all" part only happens if the result is valid. They work together: atomicity prevents partial states, consistency prevents invalid states.
Isolation
When there are concurrent writes from two different transactions, the two transactions are isolated from each other. The most strict isolation is serializability, where each transaction acts like it is the only transaction running in the database. However, this is hard to implement in reality, so we often adopt looser isolation levels.
Isolation Levels (from weakest to strongest)
| Level | Dirty Read | Non-Repeatable Read | Phantom Read | Performance |
|---|---|---|---|---|
| Read Uncommitted | Yes | Yes | Yes | Fastest |
| Read Committed | No | Yes | Yes | Fast |
| Repeatable Read | No | No | Yes | Moderate |
| Serializable | No | No | No | Slowest |
Common concurrency problems
- Dirty Read — reading uncommitted data from another transaction that might roll back
- Non-Repeatable Read — reading the same row twice and getting different values because another transaction modified it in between
- Phantom Read — re-executing a query and getting a different set of rows because another transaction inserted/deleted matching rows
How databases implement isolation
- Locking — row-level, page-level, or table-level locks to prevent concurrent modifications
- MVCC (Multi-Version Concurrency Control) — each transaction sees a snapshot of the database at a point in time (used by PostgreSQL, MySQL InnoDB)
- Serializable isolation — can use two-phase locking (2PL) or serializable snapshot isolation (SSI)
Durability
Data is persisted after a transaction is committed even in the event of a system failure. In a distributed system, this means the data is replicated to some other nodes.
How it works
- Write-Ahead Log (WAL) — changes are written to an append-only log on disk before being applied to the main data files
- Flush to disk — the database calls
fsync()to ensure data is physically written, not just in the OS page cache - Replication — in distributed systems, the transaction is not considered committed until enough replicas acknowledge the write
Transaction commits:
1. Write changes to WAL → fsync to disk
2. Apply changes to data pages (can be lazy)
3. Return success to client
If crash happens after step 1:
→ On recovery, replay WAL to restore committed transactions
ACID vs BASE
Not all databases provide full ACID guarantees. Distributed NoSQL databases often follow the BASE model instead:
| ACID | BASE | |
|---|---|---|
| Consistency | Strong consistency | Eventual consistency |
| Availability | May block during failures | Always available |
| Isolation | Strict isolation | Loose isolation |
| Latency | Higher (sync operations) | Lower (async operations) |
| Use case | Financial, OLTP systems | High-throughput, real-time systems |
Key Takeaways
- Atomicity — transactions are all-or-nothing; partial writes are rolled back
- Consistency — data must satisfy all defined constraints and invariants after every transaction
- Isolation — concurrent transactions don't interfere with each other; stronger isolation = lower performance
- Durability — committed data survives crashes; ensured by WAL, fsync, and replication
- ACID is a spectrum — real databases offer configurable trade-offs between strictness and performance
Interview Questions
1. What does each letter in ACID stand for and why does it matter?
- Atomicity — transactions are all-or-nothing. If any step fails, the entire transaction is rolled back so the database is never left in a partial state.
- Consistency — a transaction can only bring the database from one valid state to another. All constraints, triggers, and rules must be satisfied after the transaction commits.
- Isolation — concurrent transactions don't interfere with each other. Each transaction behaves as if it were the only one running, preventing race conditions.
- Durability — once a transaction commits, the data is permanent and survives crashes, power failures, and restarts.
Without ACID, a banking app could debit one account but never credit the other, or two users could overwrite each other's data without knowing.
2. How is "consistency" in ACID different from "consistency" in the CAP theorem?
| ACID Consistency | CAP Consistency | |
|---|---|---|
| Meaning | Every transaction preserves database invariants (constraints, rules) | Every read receives the most recent write or an error |
| Scope | Single database, single transaction | Distributed system, multiple replicas |
| Mechanism | Constraints, triggers, application logic | Replication protocol (synchronous writes, quorum reads) |
| Example | A CHECK(balance >= 0) prevents negative balances | After user A updates their profile, user B immediately sees the new profile |
In short: ACID consistency is about data correctness (valid states), CAP consistency is about data currency (reading latest writes).
3. What are the four SQL isolation levels? Which concurrency problems does each one prevent?
| Isolation Level | Dirty Read | Non-Repeatable Read | Phantom Read | How it works |
|---|---|---|---|---|
| Read Uncommitted | Can happen | Can happen | Can happen | No locks on reads — sees uncommitted data from other transactions |
| Read Committed | Prevented | Can happen | Can happen | Only reads committed data (short shared locks on read) |
| Repeatable Read | Prevented | Prevented | Can happen | Keeps shared locks on all rows read until transaction ends |
| Serializable | Prevented | Prevented | Prevented | Full isolation — transactions execute as if serialized (range locks or SSI) |
Most databases default to Read Committed (PostgreSQL, SQL Server) or Repeatable Read (MySQL InnoDB).
4. How does a Write-Ahead Log (WAL) ensure both atomicity and durability?
For Atomicity:
- Before any data modification, the database writes the intended change to the WAL
- If the transaction fails mid-way, on recovery the database reads the WAL and undoes (rolls back) any incomplete transactions
- This ensures no partial writes are ever visible
For Durability:
- When a transaction commits, the WAL entry is fsynced to disk before returning success to the client
- Even if the database crashes immediately after, the WAL on disk contains all committed changes
- On recovery, the database replays (redoes) the WAL to restore all committed transactions
The WAL is the single source of truth — it's written before the actual data pages, which is why it's called "write-ahead."
5. Why don't all databases use serializable isolation by default?
- Performance overhead — serializable requires strict locking or snapshot validation, which reduces throughput significantly under concurrent workloads
- More deadlocks — the stricter the isolation, the more likely two transactions will block each other, causing deadlocks that require retries
- Most apps don't need it — Read Committed or Repeatable Read is sufficient for the majority of use cases (e.g., displaying user profiles, processing orders)
- Trade-off — databases let you choose the isolation level that matches your consistency requirements vs. performance needs
PostgreSQL offers serializable but defaults to Read Committed. You only opt into serializable when the business logic truly requires it (e.g., double-booking prevention, inventory reservation).
6. What is the difference between a dirty read and a phantom read?
| Dirty Read | Phantom Read | |
|---|---|---|
| What happens | You read uncommitted data from another transaction that might roll back | You re-run a range query and get different rows because another transaction inserted/deleted matching rows |
| Example | Transaction A writes balance = 500 (not committed yet). Transaction B reads 500. Transaction A rolls back. B read data that never existed. | Transaction A queries SELECT * FROM orders WHERE amount > 100 and gets 5 rows. Transaction B inserts a new order with amount = 200 and commits. Transaction A re-runs the query and gets 6 rows. |
| Isolation level to prevent | Read Committed (and above) | Serializable (Repeatable Read prevents it in MySQL InnoDB but not in standard SQL) |
| Scope | Affects the value of existing rows | Affects the set of rows returned by a query |
Learn More
- Database Indexing — how indexes speed up reads
- Database Replication — how data is copied across nodes for durability
- Database Sharding — partitioning data across multiple servers